파이썬

[파이썬] 캐글 타이타닉 EDA
타이타닉 데이터셋을 EDA를 해보고 시각화를 해보는 것을 목표로 해볼 것이다. 타이타닉 데이터셋 사이트 https://www.kaggle.com/c/titanic/data Titanic - Machine Learning from Disaster | Kaggle www.kaggle.com 컬럼 정보 pclass : 객실 등급 survived : 생존 유무 name : 칭호를 포함한 이름 sex : 성별 age : 나이 sibsp : 형제 혹은 부부의 수 parch : 부모, 혹은 자녀의 수 ticket : 탑승권 종류 (각 숫자가 의미하는 바는 데이터를 통해 알 수 있는 것이 없을 수 있습니다.) fare : 지불한 운임 cabin : 객실정보 embarked : 선착장정보 boat : 탈출한 보트가 있다..

[파이썬] 코랩으로 EDA 해보기 (보스턴주택가격)
코랩으로 보스턴주택가격 데이터를 EDA 해볼 것이다. (EDA : 다양한 각도에서 데이터를 분석하는 과정) 데이터셋 다운로드 위 사이트로 들어가서 데이터셋을 다운로드하면 된다. 나는 다운로드한 데이터셋을 구글드라이브에 옮겨서, 코랩으로 불러올 것이다. https://www.kaggle.com/c/house-prices-advanced-regression-techniques House Prices - Advanced Regression Techniques | Kaggle www.kaggle.com 데이터셋 컬럼 요약 구글드라이브 연동 # 구글드라이브 연동 from google.colab import drive drive.mount('/content/drive') 임포트 import pandas as pd ..
[파이썬] 데이터프레임 인덱스 편집
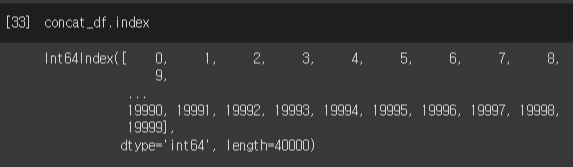
데이터프레임 병합(concat)을 하다보면 인덱스가 꼬이는 경우가 있다. 데이터 자체는 잘 붙였지만, 인덱스가 꼬여있으면 풀어야 한다. 인덱스 편집은 데이터 분석을 위해 필요한 인덱스를 설정하기 위해 필요하다. reset_index() reset_index() 사용 전 인덱스 정보 인덱스의 길이는 40000이다. 하지만, 마지막 인덱스가 19999이다. 이는 인덱스가 꼬여있음이 의심이 되는 부분이다. 꼬인 인덱스 순서 [0,1,2,3,4, ... 19997,19998,19999, 0,1,2,3,4, ... 19997,19998,19999] 0 ~ 19999 + 0 ~ 19999 : 총 길이 40000 concat_df.index reset_index() 사용 # 인덱스리셋 # reset_index() :..
[파이썬] 데이터프레임 병합 merge
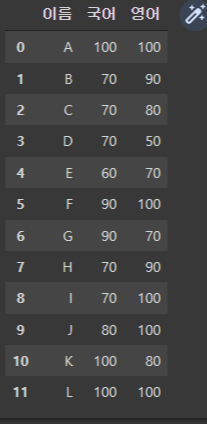
분석를 진행하다보면 데이터가 여기저기 분산되어 있는 경우가 생각보다 많다. 조각난 데이터를 분석에 필요한 데이터셋으로 만들기 위해 데이터프레임을 병합해서 사용해야 한다. 한개 이상의 데이터프레임을 병합할 때, 주로 사용하는 함수를 알아보았다. pd.merge(베이스 df, 병합할 df) - df : 데이터프레임 how : 'left' , 'right' , 'inner' , 'outer' left_on : key값이 다른 경우, 베이스 df의 key 설정 right_on : key값이 다른 경우, 병합 df의 key 설정 merge 실습 df 생성 merge_df1 = pd.DataFrame({ '이름': ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', ..

[파이썬] 데이터 분석해보기 (All Lending Club loan data)
All Lending Club loan data 간략 설명 미국 핀테크 회사인 lending club의 대출 데이터베이스이다. 클라우드펀딩과 대출을 결합한 핀테크의 시초라고 부를 수 있는 회사이며, 방대한 양의 대출 정보를 공개하면서 금융정보분석에도 기여한 공이 큰 데이터이다. 2007~2015년 대출 정보 및 개인 정보를 담고 있다. 226만건, 145항목 정보를 담고 있다. 나는 이중 4만건을 추출해서 사용할 것이다. https://www.kaggle.com/datasets/wordsforthewise/lending-club All Lending Club loan data 2007 through current Lending Club accepted and rejected loan data www.ka..

[파이썬] NaN, None, Null 차이 및 제거 방법
3 가지를 정확하게 구분하는 것이 헷갈린다. 하지만, 중요한 건 셋 다 결측치라는 것이며, 데이터 분석을 하는 과정에서 제거를 해야한다는 공통점이다. NaN(Numpy) - NaN이 포함된 연산의 결과는 NaN이 된다 None(Numpy) - Numpy에서 None을 사용하지 말 것 - None은 파이썬 객체이며, Numpy 연산이 불가능하다 - Pandas에서 사용이 가능하다. 하지만, 연산 속도가 느려지고 Numpy 메소드 사용이 불가능하다 - 사용을 권장하지 않는다 - 다른 프로그래밍 언어에서는 Null이다 NaN, None(Pandas) - Pandas에서 None은 nan으로 자동 변경된다 결측치 탐지 - isnull() : null값이 있으면 True, 아니면 False - notnull() ..

[파이썬] 넘파이(Numpy) 특수 array 생성하기
ones() - 1로 초기화한 array 생성 zeros() - 0으로 초기화한 array 생성 empty() - 빈 값으로 초기화 eye() - 항등행렬 초기화 - 항등행렬 이란 출처 : https://velog.io/@jungeun-dev/%ED%96%89%EB%A0%AC

[파이썬] 넘파이(Numpy) 함수 모음
틀린 부분이 있을 수도 있습니다. 또한 빠진 부분도 있을 수 있습니다. prod() - 원소 간의 곱셈 dot() - 내적 연산 a = np.array([1,3,5]) b = np.array([4,2,1]) np.dot(a,b) >>> 15 sum() - 원소 간의 합 cumprod() - 원소들의 누적 곱셈 cumsum() - 원소들의 누적의 합 abs() - 절댓값 sqaure() - 제곱 sqrt() - 루트 exp() - 밑이 자연상수 e인 지수함수(e^x)로 변환 log() - 밑이 e인 로그 - log2() : 밑이 2인 로그 - log10() : 밑이 10인 로그 - log_n m = math.log(m,n) : n이 밑이 된다 mean() - 평균 계산 std() - 표준 편차 계산 var..

[파이썬] EDA(탐색전 데이터 분석)란
EDA란 EDA(Exploratory Data Analysis)는 탐색적 데이터 분석을 의미합니다. 데이터를 분석하고 결과를 내는 과정이라고 할 수 있습니다. 또한, 다양한 각도에서 데이터를 관찰하고 이해하는 과정이라고도 할 수 있죠. EDA가 필요한 이유 1. 데이터의 잠재적인 문제를 발견할 수 있다 2. 데이터를 더 깊게 이해할 수 있다 3. 본격적인 작업(분석)의 흐름을 파악하는데 도움이 된다 4. 기존의 가설을 수정하거나 새로운 가설을 세울 수 있다. EDA 과정 해결하고자 하는 문제를 파악하고, 분석할 데이터를 확인한다. 분석할 데이터를 독립 변수와 종속 변수를 구분한다 파악하려는 변수가 일변량(Uni-variate)인지, 다변량(Multi-variate)인지 확인한다 관련 없는 변수가 있는지 ..
[파이썬] 코랩 파일 읽어오기 인코딩
코랩에서 구글드라이브에서 파일을 읽어오다보면 경로에 '한글'이 포함되는 경우가 있다. 그럼 에러가 발생하게 된다. 이때, 읽어온 파일 경로 뒤에 encoding = 'cp949' 를 입력하면 한글 경로를 읽을 수 있다. ex) df = pd.read_csv("파일경로/한글포함/xxx.csv" , encoding = 'cp949' )