![[파이썬] 데이터 분석해보기 (All Lending Club loan data)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fb1VayR%2FbtrAgqpZ3bj%2FAAAAAAAAAAAAAAAAAAAAAF-fIyMM6qq6JFTaQeCM9nOpBfYfN0PtlSkOoEu43-Jh%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3D9g%252FRTwGgPMULkBAwLct7qpOCJPQ%253D)
728x90
All Lending Club loan data 간략 설명
미국 핀테크 회사인 lending club의 대출 데이터베이스이다.
클라우드펀딩과 대출을 결합한 핀테크의 시초라고 부를 수 있는 회사이며,
방대한 양의 대출 정보를 공개하면서 금융정보분석에도 기여한 공이 큰 데이터이다.
2007~2015년 대출 정보 및 개인 정보를 담고 있다. 226만건, 145항목 정보를 담고 있다.
나는 이중 4만건을 추출해서 사용할 것이다.
https://www.kaggle.com/datasets/wordsforthewise/lending-club
All Lending Club loan data
2007 through current Lending Club accepted and rejected loan data
www.kaggle.com
데이터 불러오기
# '경로 입력'
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/.../loan1.csv')주요 컬럼 요약
- loan_amnt : 총 대출 금액
- funede_amnt : 갚은 금액
- term : 만기 일자
- int_rate : 이자율
- grade : 신용 등급
- emp_title : 직업명
- emp_length : 근속년수
- home_ownership : 주택 보유 여부
- issue_d : 발행 날짜
- loan_status : 현재 대출 상태(갚는 중인지, 다 갚았는지.)
head() 를 이용하여 데이터 확인하기
종종 데이터가 제대로 읽어오질 못할수도 있으니 확인하는 습관을 기르는게 좋다
df.head()
info() 를 이용하여 전반적인 정보 확인하기
- dtype 정보에서는 각 컬럼별 데이터 타입을 확인할 수 있다
- object 는 str 이라고 봐도 무방하다
- id, memer_id의 경우 "0 non-null"이라고 뜬다. 이유는 개인정보라서 삭제된 것이다
- 이와 같이 비어있는 데이터도 있을 수 있으니 확인를 해야한다
# 데이터의 전반적인 정보를 확인합니다.
df.info()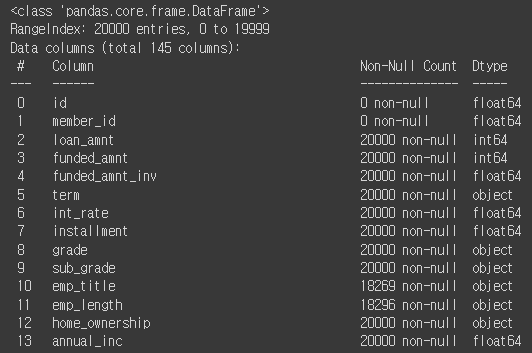
describe() 를 이용하여 기초통계량 확인하기
# 데이터의 기초통계량을 확인합니다.
df.describe()
shape 를 이용하여 배열 형태 확인하기
- 데이터 수 : 20000 개
- 컬럼 수 : 145 개
df.shape
>>> (20000, 145)데이터 접근하기(인덱싱, 슬라이싱, 샘플링)
# 첫 샘플 혹은 레코드(대출건) 데이터 보기
df.iloc[0]# 10 ~ 20번 인덱스 샘플 접근
df.iloc[10:21]# 컬럼 단위 샘플 접근
df['emp_title']# 여러 컬럼 동시 접근
df[ ['grade','sub_grade'] ]# row와 columns를 동시에 슬라이싱
# 10 ~ 20번 데이터를 grade와 sub_grade만 가져오기
df[10:21][ ['grade','sub_grade'] ]고윳값 갯수 출력
# 고윳값 갯수
df['grade'].value_counts()팬시인덱싱
bool 형태의 array를 조건을 전달하여 다차우너 배열을 인덱싱하는 방법이다.
조건식을 사용하여 분석에 필요한 데이터샘플을 추출하기 용이하다.
# 신용등급이 A인 샘플의 emp_title 확인
df[df['grade']=='A']['emp_title']
# 고유값 갯수 세기
df[df['grade']=='A']['emp_title'].value_counts()
대출 금액 평균보기
# 대출금액평균
df['loan_amnt'].mean()
>>> 15382.56875신용등급이 A와 B인 샘플 접근
# 신용등급 A와 B인 샘플접근
# 조건식을 여러개 써야 한다면 조건마다 ()로 감싸주시는 것이 좋습니다.
df[(df['grade'] == 'A') | (df['grade'] == 'B')]대출금액이 10000이상인 샘플의 신용등급 접근
# df loan_amnt 컬럼값이 10000이상인 채권샘플의 grade
df[df['loan_amnt'] > 10000]['grade']신용등급이 C 이면서, 이자률이 15% 이상인 샘플
# 신용등급 C 이면서 이자률 15% 이상 내는 샘플
df[(df['grade'] == 'C') & (df['int_rate'] > 15)]신용등급이 C와 D 일 때, annual_inc가 가장큰 샘플 접근
# df grade C 와 D 인 채권샘플 annual_inc 최대값인 인덱스 빼오기 (idxmax)
df[(df['grade']=='C') | (df['grade']=='D')]['annual_inc'].idxmax()
>>> 12357# take를 이용하여 샘플 접근
df.take([df[(df['grade']=='C') | (df['grade']=='D')]['annual_inc'].idxmax()])
대출 목적 중 'card'가 들어가는 목적 사유 살펴보기
- str 하는 이유 : 데이터가 문자형이 아닐 수 있기(int,float 등)때문에 문자형으로 변환
- contains('card') : card라는 문자가 포함되는지 확인
df[df['purpose'].str.contains('card')]['purpose']
36개월 대출과 60개월 대출의 대출 금액 파악하기
term_to_loan_amnt_dict = {}
uniq_terms = df["term"].unique()
for term in uniq_terms:
loan_amnt_sum = df.loc[df["term"] == term, "loan_amnt"].sum()
term_to_loan_amnt_dict[term] = loan_amnt_sum
term_to_loan_amnt = pd.Series(term_to_loan_amnt_dict)
term_to_loan_amnt
728x90
'파이썬' 카테고리의 다른 글
| [파이썬] 데이터프레임 인덱스 편집 (0) | 2022.04.24 |
|---|---|
| [파이썬] 데이터프레임 병합 merge (0) | 2022.04.24 |
| [파이썬] NaN, None, Null 차이 및 제거 방법 (0) | 2022.04.22 |
| [파이썬] 넘파이(Numpy) 특수 array 생성하기 (0) | 2022.04.22 |
| [파이썬] 넘파이(Numpy) 함수 모음 (0) | 2022.04.22 |