![[파이썬] NaN, None, Null 차이 및 제거 방법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fn8SHT%2FbtrAc6Ewtwq%2FAAAAAAAAAAAAAAAAAAAAAAloX9GXnPXprrj7jINF4xkeBxvNv8Ke7sZyw5Lz9Vgb%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DnWh0ea2Opb8x92jtp2XTitXn7MQ%253D)
728x90

3 가지를 정확하게 구분하는 것이 헷갈린다. 하지만, 중요한 건 셋 다 결측치라는 것이며,
데이터 분석을 하는 과정에서 제거를 해야한다는 공통점이다.
NaN(Numpy)
- NaN이 포함된 연산의 결과는 NaN이 된다
None(Numpy)
- Numpy에서 None을 사용하지 말 것
- None은 파이썬 객체이며, Numpy 연산이 불가능하다
- Pandas에서 사용이 가능하다. 하지만, 연산 속도가 느려지고 Numpy 메소드 사용이 불가능하다
- 사용을 권장하지 않는다
- 다른 프로그래밍 언어에서는 Null이다
NaN, None(Pandas)
- Pandas에서 None은 nan으로 자동 변경된다
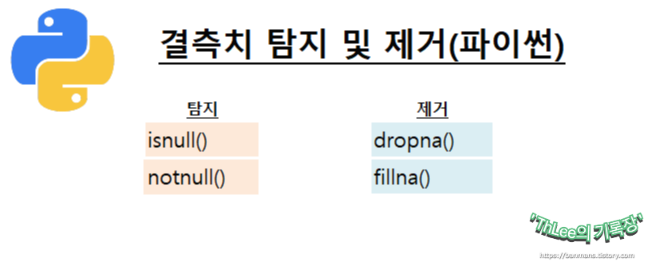
결측치 탐지
- isnull() : null값이 있으면 True, 아니면 False
- notnull() : null값이 있으면 False, 아니면 True
결측치 제거
- dropna()
dropna(
self,
axis=0,
how='any',
thresh=None,
subset=None,
inplace=False
)axis = 0 (default)
0 or 'index' = 행 삭제
1 or 'column' = 열 삭제
how = 'any' (default)
'any' = 값이 하나라도 NA면, 해당 행 또는 열을 삭제
'all' = 값이 모두 NA면, 해당 행 또는 열을 삭제
thresh = int None (default)
0개 이상의 NA값이 있으면, 삭제. thresh = 2 이면, NA가 1개면 삭제 X
subset = None
NA값을 검색할 열을 설정. ex) subset = ['name', 'age'] 이면 name과 age열에서만 NA검색
inplace = False
True면 기존 데이터에 dropna한 데이터프레임을 덮어 씌움. 원본은 삭제됨
- fillna()
fillna (
self,
value=None,
method=None,
axis=None,
inplace=False,
limit=None,
downcast=None
)value = scalar, dict, Series, or DataFrame 형의 데이터. (list는 불가)
method = None (defulat)
backfill, bfill = 다음에 오는 값으로 채우기
ffill = 이전 값으로 채우기
axis = None (default)
0 or ‘index’ = 행 방향으로 채우기
1 or ‘columns’ = 열 방향으로 채우기
inplace = False (default)
원본을 삭제하고 fillna한 값으로 변경.
limit = None (default int)
limit으로 지정한 값의 개수만큼만 fillna를 진행함.
limit = 1 이면 각 행 또는 열의 첫번째 NA만을 채움.
downcast = None (default dict)
형변환이 필요하다면 진행함.
ex) float64 to int64 (if possible)
728x90
'파이썬' 카테고리의 다른 글
| [파이썬] 데이터프레임 병합 merge (0) | 2022.04.24 |
|---|---|
| [파이썬] 데이터 분석해보기 (All Lending Club loan data) (0) | 2022.04.24 |
| [파이썬] 넘파이(Numpy) 특수 array 생성하기 (0) | 2022.04.22 |
| [파이썬] 넘파이(Numpy) 함수 모음 (0) | 2022.04.22 |
| [파이썬] EDA(탐색전 데이터 분석)란 (0) | 2022.04.22 |