![[파이썬] 캐글 타이타닉 EDA](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcwU5dc%2FbtrAEBXWZ9K%2FFJDBrRqrDIdsviiqR421S1%2Fimg.png)
타이타닉 데이터셋을 EDA를 해보고 시각화를 해보는 것을 목표로 해볼 것이다.
타이타닉 데이터셋 사이트
https://www.kaggle.com/c/titanic/data
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
컬럼 정보

- pclass : 객실 등급
- survived : 생존 유무
- name : 칭호를 포함한 이름
- sex : 성별
- age : 나이
- sibsp : 형제 혹은 부부의 수
- parch : 부모, 혹은 자녀의 수
- ticket : 탑승권 종류 (각 숫자가 의미하는 바는 데이터를 통해 알 수 있는 것이 없을 수 있습니다.)
- fare : 지불한 운임
- cabin : 객실정보
- embarked : 선착장정보
- boat : 탈출한 보트가 있다면 boat 번호
- body : 사망자의 시신 수습 후 부여한 일련번호
- home : 출신
한글 폰트 설치
저는 코랩으로 EDA를 할 것이기에, 코랩이신 분들은 코드를 그대로 복사해서 사용하시면 됩니다.
아래 코드를 실행하시고, 반드시 런타임 재시작을 해주셔야 합니다. (Runtime - Restart runtime)
# 코랩
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 런타임 재시작사용가능한 목록 확인 (필수 x)
아무 폰트가 상관 없으시면 다음으로 패스하셔도 됩니다.
# 사용가능한 폰트 목록 확인
import matplotlib.font_manager as fm
fm.get_fontconfig_fonts()한글 폰트 설정
# 한글 폰트 설정
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')임포트
# 필요모듈 import
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns마운트 (구글드라이브 연동)
from google.colab import drive
drive.mount('/content/drive')데이터 로딩 및 확인
# 데이터 로딩 및 확인
df = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/.../titanic.csv')
df.head()
데이터 info()
# 데이터 종류 확인하기
df.info()
info 정보를 보면 1309개의 샘플이 있지만, 주로 하단에 데이터가 부족한 것을 볼 수 있습니다.
그래서 결측치를 확인해볼 것입니다.
결측치 확인
for col in df.columns :
msg = '항목 {:>10}\t 비어있는 자료의 비율 : {:.2f}%'.format(col, 100 * (df[col].isnull().sum() / df[col].shape[0]))
print(msg)
import missingno as msno
msno.matrix(df=df.iloc[:,:], figsize=(8,8), color=(0.7,0.4,0.2))
하얀줄이 결측치가 있는 구간입니다. 총 데이터는 1 ~ 1309개이며, cabin이나 body가 유독 하얀 것을 볼 수 있죠.
body는 비어있는 자료의 비율이 90%, cabin은 77%이기 때문입니다.
여튼, 결측치가 많다~ 라는 것을 볼 수 있습니다
데이터 drscribe()
# 기초통계량 확인
df.describe()
1등급 객실에 승선한 여성의 생존률
df[(df['pclass'] == 1) & (df['sex'] =='female')]['survived'].sum()
>>> 139
살아남은 (1등급에 승선한)여성 수는 139명입니다.
df['survived'].count()
>>> 1309살아남은 전체 인원은 1309명입니다.
# 단순계산
df[(df['pclass'] == 1) & (df['sex'] =='female')]['survived'].sum() / df['survived'].count() * 100
>>> 10.61879297171341481등급 객실에 승선한 여성의 생존률을 구할려면 " 여성 생존률 / 전체 생존률 * 100 " 을 하면 구할 수 있습니다.
fig = plt.figure(figsize=(12,6))
df[(df['pclass'] == 1) & (df['sex'] =='female')]['survived'].value_counts().plot.pie(
explode=[0,0.1],
autopct='%1.2f%%',
)
결론 1) 전체 생존률 중 1등급 객실에 승선한 여성의 비율은 10% 이다
(참고로 전체 생존률은 38%)
결론 2) 1등급 객실에 승선한 여성들 중에 생존률은 96.5%이다
객실 등급별 생존률
객실 등급별 평균치
df.groupby('pclass').mean()
객실 등급별 생존률, 나이, 비용 등을 알 수 있습니다.
바로 알아볼 수 있는 건 1등급의 생존률은 약 60%와 평균 나이가 약 39세라는 것이다. (2등급,3등급 비슷)
객실 등급별 시각화
plt.figure(figsize=(15,8))
sns.barplot(
data = df,
x = 'pclass',
y = 'survived',
)
plt.show()
결론 ) 객실 등급이 높을수록, 생존률도 높아진다
(역시 비싼값을 하는건가...?)
전체 남녀비율
# 남녀 비율
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,2,1)
df['sex'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.2f%%',ax=graph1)
graph1.set_title('sex')
graph1.set_ylabel('')
graph2 = fig.add_subplot(1,2,2)
sns.countplot('sex',data=df,ax=graph2)
graph2.set_title('sex')
plt.show(fig)
결론 ) 남성이 여성보다 많다
전체 생존률
# 전체 생존률
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,2,1)
df['survived'].value_counts().plot.pie(
explode=[0,0.1], # 부채꼴이 벗어나는 정도
autopct='%1.2f%%', # 소수점
ax=graph1,
labels = ['Dead','Survived']
)
graph1.set_title('survived')
graph1.set_ylabel('')
graph2 = fig.add_subplot(1,2,2)
sns.countplot(
x = 'survived',
data=df,
ax=graph2,
)
graph2.set_title('survived')
plt.show(fig)
결론 ) 전체 생존률은 38%이다
성별에 따른 생존자 분류
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,2,1)
graph2 = fig.add_subplot(1,2,2)
sns.countplot(
x= 'sex',
data=df,
ax=graph1
)
graph1.set_title('Count of Passengers by Sex')
sns.countplot(
x='sex',
hue='survived',
data=df,
ax=graph2
)
graph2.set_title('Survived vs Dead')
plt.show()
결론 1) 남성이 여성보다 많다
결론 2) 여성은 생존자가 더 많고, 남성은 사망자가 더 많다
남성이 여성보다 많기에, 사망자도 더 많을까?
아니면, 남성이 여성을 지키기위해 많이 죽은 것일까?
아래에서 계속
여성끼리의 생존률과 남성끼리의 생존률
추측)
남성이 여성보다 많기에, 사망자도 더 많을까?
아니면, 남성이 여성을 지키기위해 많이 죽은 것일까?
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,2,1)
df[df['sex']=='male']['survived'].value_counts().plot.pie(
explode=[0,0.1], # 부채꼴이 벗어나는 정도
autopct='%1.2f%%', # 소수점
ax=graph1,
labels = ['Dead','Survived']
)
graph1.set_title('male')
graph1.set_ylabel('')
graph2 = fig.add_subplot(1,2,2)
df[df['sex']=='female']['survived'].value_counts().plot.pie(
explode=[0,0.1], # 부채꼴이 벗어나는 정도
autopct='%1.2f%%', # 소수점
ax=graph2,
labels = ['Dead','Survived']
)
graph2.set_title('female')
plt.show(fig)
결론 ) 남성끼리의 생존률은 19%, 여성끼리의 생존률은 27%이다.
이를 토대로 남성이 여성을 지키기 위해 희생을 했다고 볼 수 있다고 생각한다
연령, 성별, 객실등급 한번에 시각화
df['age_cat'] = pd.cut(df['age'], bins=[0, 10, 20, 50, 100],
include_lowest=True, labels=['baby', 'teenage', 'adult', 'old'])
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,3,1)
graph2 = fig.add_subplot(1,3,2)
graph3 = fig.add_subplot(1,3,3)
sns.barplot('pclass', 'survived', data=df, ax=graph1)
sns.barplot('age_cat', 'survived', data=df, ax=graph2)
sns.barplot('sex', 'survived', data=df, ax=graph3)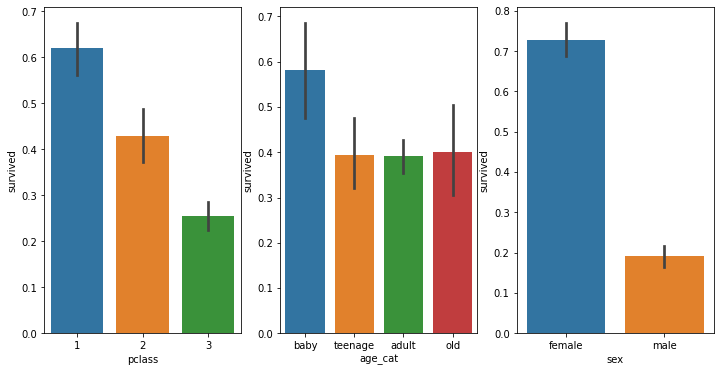
연령대별 분포 생존자, 사망자 비교
fig = plt.figure(figsize=(12,6))
graph1 = fig.add_subplot(1,1,1)
sns.kdeplot(df["age"][(df["survived"] == 0) & (df["age"].notnull())],
ax = graph1, color="Blue", shade = True)
sns.kdeplot(df["age"][(df["survived"] == 1) & (df["age"].notnull())],
ax =graph1, color="Green", shade= True)
graph1.set_xlabel("Age")
graph1.set_ylabel("Frequency")
graph1.legend(["Not Survived","Survived"])
가장 많은 대가족 승객은 어떻게 됬을까?
df['parch'].value_counts()
>>>
0 1002
1 170
2 113
3 8
4 6
5 6
6 2
9 2
Name: parch, dtype: int64승객 중 parch(부모or자녀의수)가 가장 큰 값 찾기 => 9
df['sibsp'].value_counts()
>>>
0 891
1 319
2 42
4 22
3 20
8 9
5 6
Name: sibsp, dtype: int64승객 중 silsp(형제or부부의수)가 가장 큰 값 찾기 => 8
parch와 silsp을 비교하여 더 큰 값인 '9'로 샘플링해보기
df[df['parch']== 9]
Sage, Mr. John George, Sage, Mrs. John (Annie Bullen)
Sage 부부로 나온다.
( 부부임을 판단할 수 있는 이유는 plcass가 같으며, 한명은 남자, 한명은 여자이며, 티켓의 번호가 같다는 것을 토대로 판단할 수 있다)
Sage 부부의 티켓 번호 CA. 2343로 샘플링 해보기
df[df['ticket']=='CA. 2343']
샘플링 결과...
parch가 9인 이유는 자녀가 9명임을 다시한번 알 수 있었고, 자녀들은 sibsp가 8임을 알 수 있다.(본인 제외, 형제의 수)
결론 ) 가장 많은 대가족은 전원 사망한 것을 알 수 있다. 😰
대가족 기준으로 분류해보기
df.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 pclass 1309 non-null int64
1 survived 1309 non-null int64
2 name 1309 non-null object
3 sex 1309 non-null object
4 age 1046 non-null float64
5 sibsp 1309 non-null int64
6 parch 1309 non-null int64
7 ticket 1309 non-null object
8 fare 1308 non-null float64
9 cabin 295 non-null object
10 embarked 1307 non-null object
11 boat 486 non-null object
12 body 121 non-null float64
13 home.dest 745 non-null object
14 age_cat 1046 non-null category
dtypes: category(1), float64(3), int64(4), object(7)
memory usage: 144.8+ KBdf['parch'].value_counts()
>>>
0 1002
1 170
2 113
3 8
4 6
5 6
6 2
9 2
Name: parch, dtype: int64df['family_cat'] = df['parch'] + df['sibsp']
df['family_cat'] = pd.cut(df['family_cat'], bins=[0, 0.5, 5.5, 13],
include_lowest=True, labels=['solo', 'small', 'big'])
df.head()
분류 결론 )
가족의 단위를 총 3분류로 나눴다.
family_cat을 가족의 단위로 지정했으며, solo, small, big 3분류로 나눴다.
가족을 분류하는데 사용된 컬럼은 `parch`와 `sibsp`이다.
solo는 혼자 온 승객이며, small은 5명까지, big은 그 이상이다.
가족 단위별 승객 수 시각화
fig = plt.figure(figsize=(12,8))
sns.countplot(
x= 'family_cat',
data=df,
)
plt.show()
가족 단위별 나이 분포 시각화
fig = plt.figure(figsize=(12,8))
sns.countplot(
x='family_cat',
hue='age_cat',
data=df,
)
plt.show()
가족 단위별 생존자 수 시각화
df[(df['family_cat'] == 'big') & (df['survived'])]fig = plt.figure(figsize=(12,8))
sns.countplot(
x='family_cat',
hue='survived',
data=df,
)
plt.show()
가족 단위별 객실 등급 시각화
fig = plt.figure(figsize=(12,8))
sns.countplot(
x='family_cat',
hue='pclass',
data=df,
)
plt.show()
가족 단위별 생존률 시각화
fig = plt.figure(figsize=(12,8))
sns.barplot('family_cat', 'survived', data=df)
대가족의 생존률 시각화
fig = plt.figure(figsize=(12,8))
df[(df['family_cat']=='big')]['survived'].value_counts().plot.pie(
explode=[0,0.1],
autopct='%1.2f%%',
labels = ['Dead','Survived']
)
대가족 중 어른들의 생존률 시각화
df[(df['family_cat']=='big') & (df['age_cat'] == 'adult')]
fig = plt.figure(figsize=(12,8))
df[(df['family_cat']=='big') & (df['age_cat'] == 'adult')]['survived'].value_counts().plot.pie(
explode=[0,0.1],
autopct='%1.2f%%',
labels = ['Dead','Survived']
)
대가족 중 아이들의 생존률 시각화
fig = plt.figure(figsize=(12,8))
df[(df['family_cat']=='big') & (df['age_cat'] != 'adult')]['survived'].value_counts().plot.pie(
explode=[0,0.1],
autopct='%1.2f%%',
labels = ['Dead','Survived']
)
'파이썬' 카테고리의 다른 글
| [파이썬] 코랩으로 EDA 해보기 (보스턴주택가격) (0) | 2022.04.24 |
|---|---|
| [파이썬] 데이터프레임 인덱스 편집 (0) | 2022.04.24 |
| [파이썬] 데이터프레임 병합 merge (0) | 2022.04.24 |
| [파이썬] 데이터 분석해보기 (All Lending Club loan data) (0) | 2022.04.24 |
| [파이썬] NaN, None, Null 차이 및 제거 방법 (0) | 2022.04.22 |