![[인공지능] 딥러닝 Overfitting(오버피팅) 피하는 방법!](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbvPhuQ%2FbtrFKomEXSs%2FskSkk9HZtcysxGlDriDq7k%2Fimg.png)
Avoiding overfitting
1. Dropout (2012, Geoffrey Hinton)
: Training을 진행할 때 매 Batch 마다 Layer 단위로 일정 비율 만큼의 Neuron을 꺼뜨리는 방식이다

왼쪽이 Dropout을 사용하지 않은 이미지이고, 오른쪽이 Dropout을 60%(0.6)을 적용한 이미지이다. 꺼지는 위치는 랜덤이다
랜덤하게 Neuron을 꺼뜨려 학습을 방해함으로써 모델의 학습이 Training data에 편향되는 것(over fitting)을 막아주는 것이 핵심이다.
즉, 동일한 데이터를 매번 다른 모델을 학습시키는 효과를 발생시켜 일종의 Model ensemble 효과를 얻는 것이다
가중치 값이 큰 특정 Neuron의 영향력이 커져 다른 Neuron들의 학습 속도에 문제를 발생시키는 Co-adaptation을 회피할 수 있게 한다
Dropout을 언제 적용할까?

위 이미지처럼 마지막에만 Dropout을 적용시켜주면 된다
2. Batch Normalization (2015)
Input data에 대해 Standardization 과 같은 Normalization을 적용하면 전반적으로 model의 성능이 높아진다
데이터 내 Columns 들의 Scale 에 model 이 너무 민감해지는 것을 막아주기 때문이다
신경망에 경우, Normalization이 제대로 적용되지 않으면, 최적의 cost 지점으로 가는 길을 빠르게 차지 못하게 된다

Input data 뿐만 아니라, 신경망 내부의 중간에 있는 Hidden layer로의 input 에도 적용해주는 것이 BN(Batch Normalization)이다
활성화 함수를 적용하기 전에 Batch Normalization을 먼저 적용(앞과 뒤 중 어느쪽에 삽입할지는 논의/실험 중)
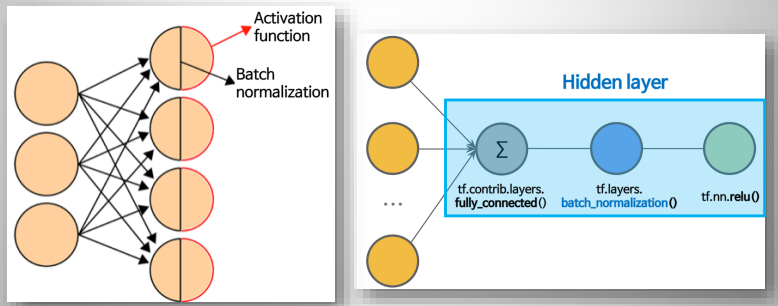
Procsess of Batch Normalization (during training)
1. 각 hidden layer 로의 input data에 대해 평균이 0, 분산이 1이 되도록 normalization을 진행(출력값이 선형성이 됨)
2. hidden layer 의 출력값(output)이 비선형성을 유지할 수 있도록, normalization의 결과에 Scaling & Shifting 적용
3. Scaling & Shifting을 적용한 결과를 활성화 함수에게 전달 후 hidden layer의 최종 output 계산
BN 장점

핵심은 학습 속도의 향상이다.
물론 BN을 사용하면 overfitting이 줄어들지만 부수적인 효과라고 보는 것이 좋다
Neural Network Optimization - Summary

입력층은 input layer, 은닉층은 hidden layer, 출력층은 output layer이며, 은닉층에서 활성 함수(Activation Function)을 사용하게 되며, 종류로는 계단함수, tanh, sigmoid, ReLU, ELU 등이 있다. 활성 함수를 사용하는 이유는 선형 함수를 비선형 함수로 만들기 위함이다.
Drop out은 overfitting을 줄이기 위한 방식이다.
층 개수, 정규화, Batch size, epoch, 노드 개수, 손실함수, Learing rate는 하이퍼 파라미터이다.
'인공지능' 카테고리의 다른 글
| [인공지능] 딥러닝 강의, 구현, 체험 등 사이트 모음집 (0) | 2022.07.01 |
|---|---|
| [인공지능] Detectron2 - Github (0) | 2022.06.26 |
| [인공지능] train_test_split 하는 이유는 무엇일까? (0) | 2022.06.22 |