![[파이썬] 판다스 캐글 타이타닉 데이터 불러와 맛만 보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpX2gn%2FbtrzQGTLER3%2FFTKpNyBTo4TuWcCMt2ySJ0%2Fimg.png)
캐글 중 가장 유명한 문제는 타이타닉인거 같다. 여기저기 인공지능 관련된 영상이나 책을 보면
캐글에 참여해보라고 추천한다. 캐글 문제 중에서 타이타닉은 꼭 풀어보라고 했다.
나는 아직 데이터를 가지고 유효한 결과를 도출할 수 있는 수준이 아니기에 간단히 데이터를 불러오고 데이터를 보는 정도만 해볼려 한다.
데이터 파일 다운로드
https://www.kaggle.com/c/titanic/data
Titanic - Machine Learning from Disaster | Kaggle
www.kaggle.com
위 주소로 들어가 데이터 파일(csv) 3개가 있다. gender_submission.csv, test,csv, train.csv를 다운로드 하면 된다.
나는 코랩을 통해 파일을 확인했기에 로컬에서 확인하면 다를수 있다.
코랩에서 구글드라이브 연동하기
from google.colab import drive
drive.mount('/content/drive')train.csv 파일 불러오기
train.csv파일을 불러오기 위해서는 경로를 지정해줘야 한다. 이 경로는 모두 다르므로 주의해주세요(경로 틀리면 못불러옴)
불러온 데이터를 보면 891개의 데이터(row)와 12개의 속성(columns)이 있다.
import pandas as pd
# train.csv 파일 불러오기
titanic = pd.read_csv("경로 입력") # 경로 ex) /data/titanic/train.csv
titanic
csv 파일 정보 요약 보기 : info()
info()를 이용하여 csv파일을 간단히 요약해서 볼 수 있다.(난 아직 봐도 뭔지 1도 모름ㅎㅎ)
간단히 보자면....
- columns은 12개다
- index는 891개이며, 0 ~ 890까지이다
- 12개의 columns의 타입은 int64, object, float64로 이루어져 있다
- columns 중 Age, Cabin, Embarked는 데이터가 각각 891개가 아니다. (빈 데이터가 있다)
- 데이터 타입별로 개수를 알 수 있다 (float64 : 2개, int64 : 5개, object : 5개)
- 메모리는 83.7+ KB를 사용한다
titanic.info()
>>>
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBcsv 파일 각종 통계 정보 보기 : describe()
titanic.describe()
특정 조건에 맞게 데이터 보기
# 데이터 값별 갯수
titanic["Pclass"].value_counts()
# Age 데이터가 null인 사람들만 보기
titanic[titanic.Age.isnull()]
# 0 ~ 100 순서대로 이름 보기
titanic.loc[0:100, "Name"]
# 0 ~ 100 순서대로 PassengerId ~ Age 보기
titanic.loc[0:100, "PassengerId" : "Age"]
# 100 ~ 200 순서대로 헤더 0 1 2 보기
titanic.iloc[100:200, :3]
# 나이가 30 이상인 사람들만 보기
titanic[titanic.Age > 30]피벗 테이블(Pivot Table) 사용하여 데이터 살펴보기
1. 성별을 기준으로 생존률 파악해보기
아래 코드는 순서대로 차근차근 나아가는 구조입니다(난 아직 초보라서 한 번에 쓰면 못알아봄...😂😂)
# 성별을 기준으로 생존률 파악 --> Mean vs Sum
pd.pivot_table(data=titanic, index=["Sex"])
pd.pivot_table(data=titanic, index=["Sex"], values = ["Survived"])
pd.pivot_table(data=titanic, index=["Sex"], values = ["Survived"], aggfunc = ["sum"])
pd.pivot_table(data=titanic, index=["Sex"], values=["Survived"], aggfunc = ["sum","mean","count"])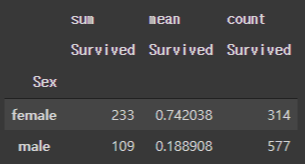
(틀릴수도 있지만) "성별을 기준으로 생존률을 파악"해본다면, 여성의 총 314명 중에서 233명만 살아남았으며, 이는 74%에 해당한다. 남자의 총 577명 중에서 109명만 살아남았으며, 이는 18%에 해당한다. 이를 통해 성별을 기준으로 생존률만 따진다면 남성보다 여성의 생존률이 높음을 알 수 있다.(틀리면 댓글좀 😥😥)
2. 객실 등급을 기준으로 생존률 파악해보기
# 사회 계급(객실 등급)을 기준으로 생존률 파악
pd.pivot_table(data=titanic, index = ["Pclass"], values = ["Survived"])
pd.pivot_table(data=titanic, index = ["Pclass", "Sex"], values = ["Survived"])
pd.pivot_table(data=titanic, index = ["Pclass", "Sex"], values = ["Survived"], aggfunc = ["mean", "count"])

(틀릴수도 있지만) "객실 등급을 기준으로 생존률"을 파악해본다.
성별을 무시하고 분석을 해본다면,
1클래스는 총 216명이며, 생존자는 136명이다. 생존률은 약 63%이다.
2클래스는 총 184명이며, 생존자는 87명이다. 생존률은 약 47%이다.
3클래스는 총 491명이며, 생존자는 119명이다. 생존률은 약 24%이다.
(사실 mean Survived는 뭘 의미하는지 모르겠다. 그냥 총인원 / 생존자를 토대로 단순히 생존률을 계산했다)
결론적으로 "객실 등급에 따른 생존률"은 객실 등급이 높을수록 생존률이 높음을 알 수 있다.
다음은 "객실 등급과 성별에 따른 생존률"를 분석해본다면,
1클래스는 총 여성 94명 중, 91명이 생존했다. 이는 약 97%가 생존했음을 알 수 있다. 총 남성 122명 중, 45명이 생존했으며, 약 37%가 생존했음을 알 수 있다.
2클래스는 총 여성 76명 중 70명이 생존 했으며, 약 92%가 생존했음을 알 수 있다. 총 남성 108명 중 17명이 생존했으며, 약 16%가 생존했음을 알 수 있다.
3클래스는 총 여성 144명 중 72명이 생존 했으며, 약 50%가 생존했음을 알 수 있다. 총 남성 347명 중 약 47명이 생존했으며, 약 14%가 생존했음을 알 수 있다.
결론적으로 "객실 등급과 성별에 따른 생존률"은 객실 등급이 높을수록 (성별 상관없이)생존률이 높음을 알 수 있으며, 여성이 남성보다 생존률이 높음을 알 수 있다. 객실 등급과 성별은 연관성이 크게 없어보이며, 각각이 생존률에 영향을 미치는 것 같다.
(이렇게 분석하는게 맞나??????🙄🙄🙄)
'파이썬' 카테고리의 다른 글
| [파이썬] 코랩 파일 읽어오기 인코딩 (0) | 2022.04.21 |
|---|---|
| [파이썬] 코랩(Colab)과 구글드라이브 연동하기(마운트) (0) | 2022.04.21 |
| [파이썬] 판다스(Pandas) 메서드 실습 (0) | 2022.04.18 |
| [파이썬] OOP 객체 지향 프로그래밍 (0) | 2022.04.18 |
| [파이썬] 넘파이(Numpy) 메서드 실습 (0) | 2022.04.15 |