![base line [데이콘 제공] 코드 리뷰](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FG156N%2FbtrVBR0ybFL%2FwzJ7lcm6QzyeNyRrFhLEC1%2Fimg.png)
https://dacon.io/competitions/official/236037/codeshare/7260?page=1&dtype=recent
[Baseline] TfidfVectorizer + MLP
문장 유형 분류 AI 경진대회
dacon.io
- 사용 환경
- 코랩
- cpu 기준 : 10 epochs 7분 소요(학습)
- 결과 : 0.5343 (base line 변경없이, 10 epochs)
순서
- 마운트 & 임포트
- 하이퍼파라미터 설정
- Seed 설정
- Data load
- Train test split
- Processing(전처리)
- 문장(Text) 벡터화
- Label Encoding(유형,극성,시제,확실성)
- DataSet & DataLoader
- Model
- Train 함수
- Valid 함수
- Run!!
- Inference
- Submission
00. 마운트
from google.colab import drive
drive.mount('/content/drive')코랩에서 데이터를 불러오기 위해 마운트를 해준다
01. Import
import random
import pandas as pd
import numpy as np
import os
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import preprocessing
from sklearn.metrics import f1_score
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from tqdm.auto import tqdm
import warnings
warnings.filterwarnings(action='ignore')device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
device02. 하이퍼 파라미터 설정
CFG = {
'EPOCHS':10,
'LEARNING_RATE':1e-4,
'BATCH_SIZE':256,
'SEED':41
}- epochs : 학습량
- learning_rate : optimizer에 사용
- batch_size : dataloader에 사용
- seed : 시드 고정용
03. Seed 설정
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(CFG['SEED']) # Seed 고정시드를 고정하지 않으면 코랩에서 똑같이 돌려도 어제와 내일 결과가 다를수 있다
04. Data load
data_dir = '경로입력'
df = pd.read_csv(os.path.join(data_dir,'train.csv'))
test = pd.read_csv(os.path.join(data_dir,'test.csv'))data_dir에 '경로입력' 대신 데이터 디렉토리를 입력해주면 된다
05. Train_test_split
# 제공된 학습데이터를 학습 / 검증 데이터셋으로 재 분할
train, val, _, _ = train_test_split(df, df['label'], test_size=0.2, random_state=CFG['SEED'])train 데이터를 train과 valid로 8:2로 나누어준다
06. Processing
06.1. 문장(Text) 벡터화
# 1. 문장(Text) 벡터화 -> TfidfVectorizer
vectorizer = TfidfVectorizer(min_df = 4, analyzer = 'word', ngram_range=(1, 2))
vectorizer.fit(np.array(train["문장"]))
train_vec = vectorizer.transform(train["문장"])
val_vec = vectorizer.transform(val["문장"])
test_vec = vectorizer.transform(test["문장"])
print(train_vec.shape, val_vec.shape, test_vec.shape)
왜 할까?
문장을 벡터화(숫자)로 변경해주기 위함이다.
어떻게 바뀔까?
before : 0.75%포인트 금리 인상은 1994년 이후 28년 만에 처음이다.
after : [0. 0. 0.448420 ... 0.281466 0. 0.]
after 리스트의 길이는 9351이다. 그렇기에 모두 표시가 안되지만, before 문장에서 각 단어에 해당하는 단어의 값이 들어가 있다.(참고로 0.448420 과 0.281466은 보여주기 위해서 임의로 넣은 값이다)
더 구체적인 예시를 함보자!
a = sorted(vectorizer.vocabulary_.items(), key = lambda x : x[1], reverse=True)
print(a[:3])
vectorizer의 vocabulary를 보면 제일 마지막(9351개 중 인덱스 9350)은 '힘차게' 라는 단어가 들어간다.
실제로 문장(Text)중에 '힘차게' 들어가있는 문장을 변환해서 결과를 함보자!!
a = vectorizer.transform(['지층을 뚫고 힘차게 올라와 있는 힘을 다 해 '으자자자자!' 올라오며 원래 지상에 있던 암석들이 흩어져버리고, 새로운 산이 솟아오른 것이다'])
print('before :',train["문장"].loc[10137])
print('after :',a.toarray())
문장에 '힘차게'가 들어가 있다. '힘차게' 인덱스 위치에 0.40605625가 들어있다. 즉, '힘차게'라는 단어를 벡터화하면 0.40605625가 된다. 이와 같이 모든 단어가 벡터화가 된다.
06.2. Label Encoding(유형,극성,시제,확실성)
# 2. Label Encoding (유형, 극성, 시제, 확실성)
type_le = preprocessing.LabelEncoder()
train["유형"] = type_le.fit_transform(train["유형"].values)
val["유형"] = type_le.transform(val["유형"].values)
polarity_le = preprocessing.LabelEncoder()
train["극성"] = polarity_le.fit_transform(train["극성"].values)
val["극성"] = polarity_le.transform(val["극성"].values)
tense_le = preprocessing.LabelEncoder()
train["시제"] = tense_le.fit_transform(train["시제"].values)
val["시제"] = tense_le.transform(val["시제"].values)
certainty_le = preprocessing.LabelEncoder()
train["확실성"] = certainty_le.fit_transform(train["확실성"].values)
val["확실성"] = certainty_le.transform(val["확실성"].values)왜 할까?
- 유형
- 대화형 -> 0
- 사실형 -> 1
- 예측형 -> 2
- 추론형-> 3
- 극성
- 긍정 -> 0
- 미정 -> 1
- 부정 -> 2
- 시제
- 과거 -> 0
- 미래 -> 1
- 현재 -> 2
- 확실성
- 불확실 -> 0
- 확실 -> 1
각각을 위와 같이 변경해주는 역할을 한다
train_type = train["유형"].values # sentence type
train_polarity = train["극성"].values # sentence polarity
train_tense = train["시제"].values # sentence tense
train_certainty = train["확실성"].values # sentence certainty
train_labels = {
'type' : train_type,
'polarity' : train_polarity,
'tense' : train_tense,
'certainty' : train_certainty
}val_type = val["유형"].values # sentence type
val_polarity = val["극성"].values # sentence polarity
val_tense = val["시제"].values # sentence tense
val_certainty = val["확실성"].values # sentence certainty
val_labels = {
'type' : val_type,
'polarity' : val_polarity,
'tense' : val_tense,
'certainty' : val_certainty
}train과 valid의 label(정답)을 DataSet에 넣기위해서 따로 딕셔너리로 만들어준다
07. Dataset
class CustomDataset(Dataset):
def __init__(self, st_vec, st_labels):
self.st_vec = st_vec
self.st_labels = st_labels
def __getitem__(self, index):
st_vector = torch.FloatTensor(self.st_vec[index].toarray()).squeeze(0)
if self.st_labels is not None:
st_type = self.st_labels['type'][index]
st_polarity = self.st_labels['polarity'][index]
st_tense = self.st_labels['tense'][index]
st_certainty = self.st_labels['certainty'][index]
return st_vector, st_type, st_polarity, st_tense, st_certainty
else:
return st_vector
def __len__(self):
return len(self.st_vec.toarray())__getitem__ 안에 있는 "st_vector = torch.FloatTensor(self.st_vec[index].toarray()).squeeze(0)" 거치게 되면 어떻게 되고, 들어가는 데이터는 무엇일까?
for i in train_vec:
print(i)
print('-'*50)
print(i.toarray())
print('-'*50)
print(torch.FloatTensor(i.toarray()))
print('-'*50)
print(torch.FloatTensor(i.toarray()).squeeze(0))
break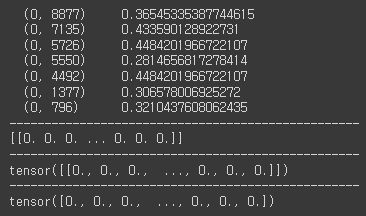
들어가는 데이터는 아래와 같다
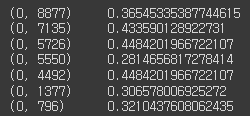
위 데이터가 toarray()를 거치게 되면, 1번째 줄을 예시로 보자!
"(0, 8877) 0.36545335387744615" 에서 (0, 8877) 의 의미는 0은 별 의미 없고(틀리면 지적좀), 8877이란 의미는 인덱스를 의미한다. 0.3654는 tf-idf값이 된다. 즉, 8877 인덱스에 0.3654가 들어간다고 보면 된다.
toarray()를 거치게 되면 "[[0. 0. 0. ... 0. 0. 0.]]"이 된다. 너무 길어서 다 표시는 안되지만, 인덱스 8877에는 0.3654이 들어가 있다.
squeeze(0)를 거치게 되면 "tensor([0., 0., 0., ..., 0., 0., 0.])" 이 된다. 2중에서 1중으로 바뀌게 된다.
train_dataset = CustomDataset(train_vec, train_labels)
train_loader = DataLoader(train_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=True, num_workers=0)
val_dataset = CustomDataset(val_vec, val_labels)
val_loader = DataLoader(val_dataset, batch_size = CFG['BATCH_SIZE'], shuffle=False, num_workers=0)데이터셋과 데이터로드를 생성해준다.
08. Model 정의
class BaseModel(nn.Module):
def __init__(self, input_dim=9351):
super(BaseModel, self).__init__()
self.feature_extract = nn.Sequential(
nn.Linear(in_features=input_dim, out_features=1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(),
nn.Linear(in_features=1024, out_features=1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(),
nn.Linear(in_features=1024, out_features=512),
nn.BatchNorm1d(512),
nn.LeakyReLU(),
)
self.type_classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features=512, out_features=4),
)
self.polarity_classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features=512, out_features=3),
)
self.tense_classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features=512, out_features=3),
)
self.certainty_classifier = nn.Sequential(
nn.Dropout(p=0.3),
nn.Linear(in_features=512, out_features=2),
)
def forward(self, x):
x = self.feature_extract(x)
# 문장 유형, 극성, 시제, 확실성을 각각 분류
type_output = self.type_classifier(x)
polarity_output = self.polarity_classifier(x)
tense_output = self.tense_classifier(x)
certainty_output = self.certainty_classifier(x)
return type_output, polarity_output, tense_output, certainty_output일단 label이 유형, 극성, 시제, 확실성 각각 만들어주기 위해 output를 만들어준다
09. Train 함수
def train(model, optimizer, train_loader, val_loader, scheduler, device):
model.to(device)
criterion = {
'type' : nn.CrossEntropyLoss().to(device),
'polarity' : nn.CrossEntropyLoss().to(device),
'tense' : nn.CrossEntropyLoss().to(device),
'certainty' : nn.CrossEntropyLoss().to(device)
}
best_loss = 999999
best_model = None
for epoch in range(1, CFG['EPOCHS']+1):
model.train()
train_loss = []
for sentence, type_label, polarity_label, tense_label, certainty_label in tqdm(iter(train_loader)):
sentence = sentence.to(device)
type_label = type_label.to(device)
polarity_label = polarity_label.to(device)
tense_label = tense_label.to(device)
certainty_label = certainty_label.to(device)
optimizer.zero_grad()
type_logit, polarity_logit, tense_logit, certainty_logit = model(sentence)
loss = 0.25 * criterion['type'](type_logit, type_label) + \
0.25 * criterion['polarity'](polarity_logit, polarity_label) + \
0.25 * criterion['tense'](tense_logit, tense_label) + \
0.25 * criterion['certainty'](certainty_logit, certainty_label)
loss.backward()
optimizer.step()
train_loss.append(loss.item())
val_loss, val_type_f1, val_polarity_f1, val_tense_f1, val_certainty_f1 = validation(model, val_loader, criterion, device)
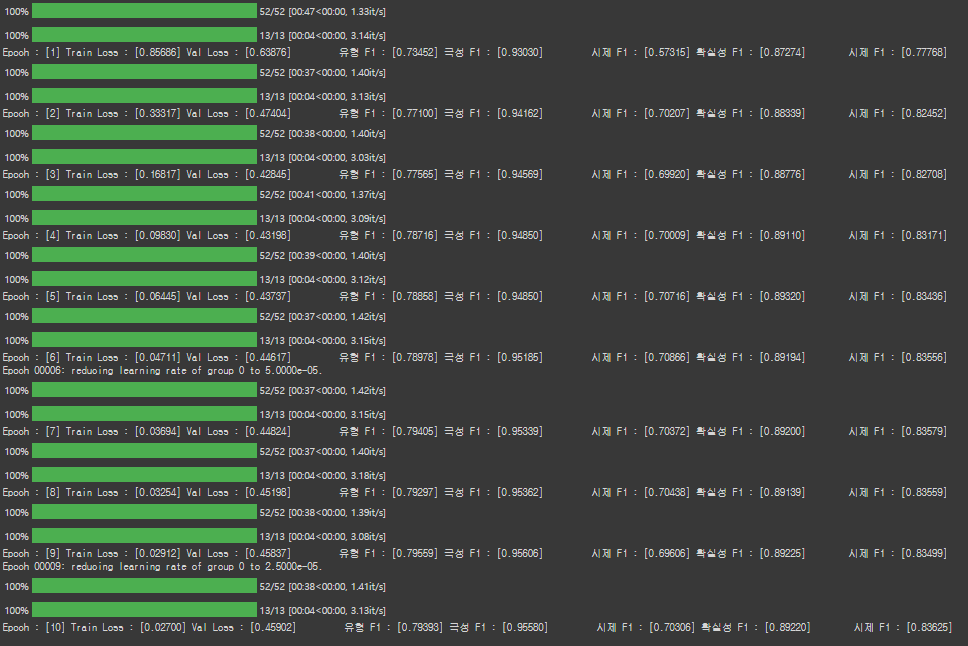
print(f'Epoch : [{epoch}] Train Loss : [{np.mean(train_loss):.5f}] Val Loss : [{val_loss:.5f}] \
유형 F1 : [{val_type_f1:.5f}] 극성 F1 : [{val_polarity_f1:.5f}] \
시제 F1 : [{val_tense_f1:.5f}] 확실성 F1 : [{val_certainty_f1:.5f}]\
시제 F1 : [{(val_type_f1+val_polarity_f1+val_tense_f1+val_certainty_f1)/4:.5f}] \
')
if scheduler is not None:
scheduler.step(val_loss)
if best_loss > val_loss:
best_loss = val_loss
best_model = model
return best_model10. Valid 함수
def validation(model, val_loader, criterion, device):
model.eval()
val_loss = []
type_preds, polarity_preds, tense_preds, certainty_preds = [], [], [], []
type_labels, polarity_labels, tense_labels, certainty_labels = [], [], [], []
with torch.no_grad():
for sentence, type_label, polarity_label, tense_label, certainty_label in tqdm(iter(val_loader)):
sentence = sentence.to(device)
type_label = type_label.to(device)
polarity_label = polarity_label.to(device)
tense_label = tense_label.to(device)
certainty_label = certainty_label.to(device)
type_logit, polarity_logit, tense_logit, certainty_logit = model(sentence)
loss = 0.25 * criterion['type'](type_logit, type_label) + \
0.25 * criterion['polarity'](polarity_logit, polarity_label) + \
0.25 * criterion['tense'](tense_logit, tense_label) + \
0.25 * criterion['certainty'](certainty_logit, certainty_label)
val_loss.append(loss.item())
type_preds += type_logit.argmax(1).detach().cpu().numpy().tolist()
type_labels += type_label.detach().cpu().numpy().tolist()
polarity_preds += polarity_logit.argmax(1).detach().cpu().numpy().tolist()
polarity_labels += polarity_label.detach().cpu().numpy().tolist()
tense_preds += tense_logit.argmax(1).detach().cpu().numpy().tolist()
tense_labels += tense_label.detach().cpu().numpy().tolist()
certainty_preds += certainty_logit.argmax(1).detach().cpu().numpy().tolist()
certainty_labels += certainty_label.detach().cpu().numpy().tolist()
type_f1 = f1_score(type_labels, type_preds, average='weighted')
polarity_f1 = f1_score(polarity_labels, polarity_preds, average='weighted')
tense_f1 = f1_score(tense_labels, tense_preds, average='weighted')
certainty_f1 = f1_score(certainty_labels, certainty_preds, average='weighted')
return np.mean(val_loss), type_f1, polarity_f1, tense_f1, certainty_f111. Run!!
model = BaseModel()
model.eval()
optimizer = torch.optim.Adam(params = model.parameters(), lr = CFG["LEARNING_RATE"])
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2,threshold_mode='abs',min_lr=1e-8, verbose=True)
infer_model = train(model, optimizer, train_loader, val_loader, scheduler, device)model을 불러오고,
optimizer은 Adam을 사용한다.
scheduler은 ReduceLROnPlateau를 사용한다.
12. Inference
test_dataset = CustomDataset(test_vec, None)
test_loader = DataLoader(test_dataset, batch_size=CFG['BATCH_SIZE'], shuffle=False, num_workers=0)def inference(model, test_loader, device):
model.to(device)
model.eval()
type_preds, polarity_preds, tense_preds, certainty_preds = [], [], [], []
with torch.no_grad():
for sentence in tqdm(test_loader):
sentence = sentence.to(device)
type_logit, polarity_logit, tense_logit, certainty_logit = model(sentence)
type_preds += type_logit.argmax(1).detach().cpu().numpy().tolist()
polarity_preds += polarity_logit.argmax(1).detach().cpu().numpy().tolist()
tense_preds += tense_logit.argmax(1).detach().cpu().numpy().tolist()
certainty_preds += certainty_logit.argmax(1).detach().cpu().numpy().tolist()
return type_preds, polarity_preds, tense_preds, certainty_predstype_preds, polarity_preds, tense_preds, certainty_preds = inference(model, test_loader, device)type_preds = type_le.inverse_transform(type_preds)
polarity_preds = polarity_le.inverse_transform(polarity_preds)
tense_preds = tense_le.inverse_transform(tense_preds)
certainty_preds = certainty_le.inverse_transform(certainty_preds)predictions = []
for type_pred, polarity_pred, tense_pred, certainty_pred in zip(type_preds, polarity_preds, tense_preds, certainty_preds):
predictions.append(type_pred+'-'+polarity_pred+'-'+tense_pred+'-'+certainty_pred)13. Submission
submit = pd.read_csv('경로입력')
submit['label'] = predictionssubmit.head()submit.to_csv('./baseline_submit.csv', index=False)train, valid, inference, submission 부분은 코드 보면 금방 이해될거 같아서 따로 설명을 쓰지 않았다.
대신, processing(전처리) 부분을 위주로 설명을 넣었다.