
728x90
Korean Word2Vec
ABOUT 이곳은 단어의 효율적인 의미 추정 기법(Word2Vec 알고리즘)을 우리말에 적용해 본 실험 공간입니다. Word2Vec 알고리즘은 인공 신경망을 생성해 각각의 한국어 형태소를 1,000차원의 벡터 스페이
word2vec.kr
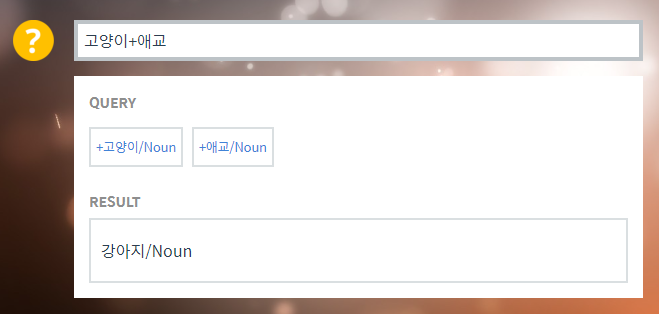
고양이 + 애교 = 강아지
한국 - 서울 + 도쿄 = 일본
박찬호 - 야구 + 축구 = 호나우두
분산 표현(Distributed Prpresentation)
희소 표현(sparse representation) 방법은 하나의 값만 1이고, 나머지는 전부 0으로 표현되는 벡터 표현 방법이다. 원-핫 인코딩을 통해서 생성된다.
분산 표현(distributed representation) 방법은 기본적으로 분포 가설(distributional hypothesis)이라는 가정 하에 만들어진 표현 방법이다. 이 가정은 '비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다'라는 가정한다.
예를 들어, 강아지란 단어는 귀엽다, 예쁘다, 애교 등의 단어와 주로 함께 등장한다. 이를 벡터화를 한다면 의미적으로 가까운 단어가 된다.
그렇다면 어떻게 가까운 단어로 찾아낼 수 있을까?
Word2Vec에는 2가지 방식이 있다.
- CBOW(Continuous Bag of Words)
- 주변에 있는 단어들을 가지고, 중간에 있는 단어들을 예측하는 방법
- Skip-Gram
- 중간에 있는 단어로 주변 단어들을 예측하는 방법
출처 : https://wikidocs.net/60854
03. 워드투벡터(Word2Vec)
앞서 원-핫 인코딩 챕터에서 원-핫 벡터는 단어 간 유사도를 계산할 수 없다는 단점이 있음을 언급한 적이 있습니다. 그래서 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터…
wikidocs.net
728x90
'자연어처리(NLP)' 카테고리의 다른 글
| TF-IDF 해석 방법(+ 예제, 실험) (0) | 2023.01.05 |
|---|---|
| Skip-gram (0) | 2022.12.16 |
| CBOW(Continuous Bag of Words) (2) | 2022.12.16 |
| 워드 임베딩(Word Embedding) (0) | 2022.12.16 |
| NLP에서 원-핫 인코딩(One-hot encoding)이란? (0) | 2022.12.16 |