파이썬
[파이썬] 코랩으로 EDA 해보기 (보스턴주택가격)
ThLee
2022. 4. 24. 18:41
728x90
코랩으로 보스턴주택가격 데이터를 EDA 해볼 것이다.
(EDA : 다양한 각도에서 데이터를 분석하는 과정)
데이터셋 다운로드
위 사이트로 들어가서 데이터셋을 다운로드하면 된다.
나는 다운로드한 데이터셋을 구글드라이브에 옮겨서, 코랩으로 불러올 것이다.
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
House Prices - Advanced Regression Techniques | Kaggle
www.kaggle.com
데이터셋 컬럼 요약

구글드라이브 연동
# 구글드라이브 연동
from google.colab import drive
drive.mount('/content/drive')임포트
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns한글 폰트 설치
# 한글 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf
# 런타임재시작한글 폰트는 설치를 해주고 런타임재시작을 해줘야 적용이 된다.
한글 폰트 설정
# 한글 폰트 설정
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')데이터셋 불러오기
head()는 데이터셋의 상위 5개를 볼 수 있다.
df = pd.read_excel('/content/drive/MyDrive/Colab Notebooks/.../BostonHousing.xls')
df.head()
데이터 요약정보
df.info()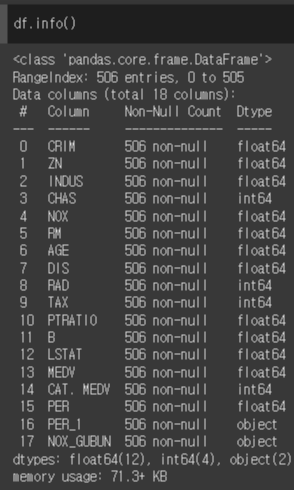
결측값 갯수 확인
df.isna().sum()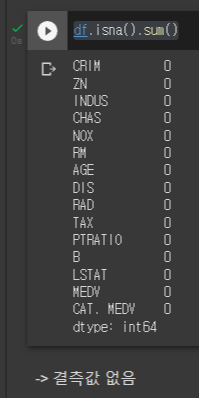
데이터의 상관관계
df.corr()상관관계 높은 순으로 출력
# 상관관계가 높은 순으로 출력
corr_order = df.corr().loc[:'LSTAT','MEDV'].abs().sort_values(ascending = False)
corr_order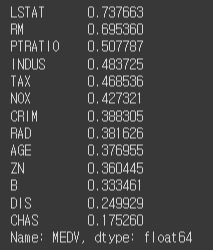

상관관계 히트맵으로 보기
corr = df.corr() # 상관관계 값 저장
fig = plt.figure(figsize = (16, 12)) # 가로 세로 사이즈 설정
axes = fig.gca() # Axes를 구해준다.
heatMap = sns.heatmap(corr.values, annot=True, fmt=".3f", cmap='Blues',
xticklabels=df.columns, yticklabels=df.columns ,
ax = axes)
plt.tight_layout() # 보기 좋도록 적정 레이아웃값 설정
plt.show()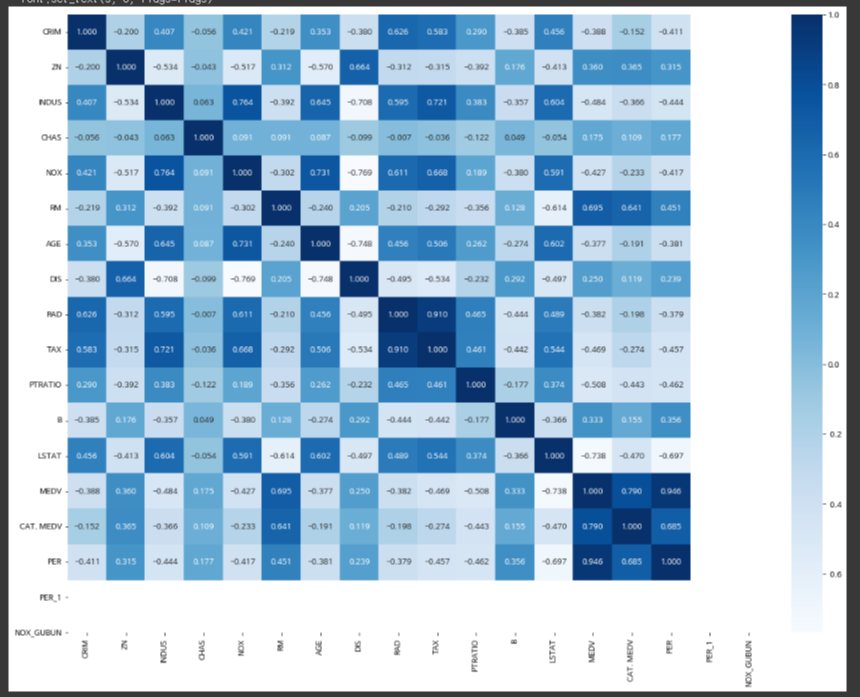
데이터 통계정보
df.describe()CASE 1. 방 하나의 가격이 높을수록 주택 가격이 비쌀 것인가?
가설
방 하나의 가격이 높을수록, 주택 가격이 높을 것이다.
방 하나당 가격 컬럼 생성
df['PER'] = df['MEDV'].div(df['RM'])
df.head()
방 하나당 가격의 평균
# 방 하나당 가격의 평균
df['PER'].mean()
>>> 3.5262676384090534평균 이상의 샘플 보기
# 평균 이상의 샘플 접근
cond = df['PER'] >= 3.52
df.loc[cond]
방 하나당 가격과 주택 가격 데이터 시각화
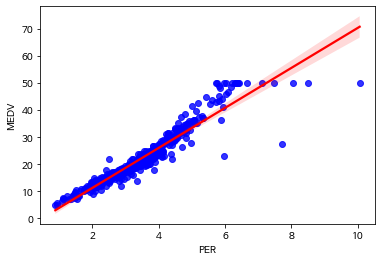
그래프 분석
(주관적인 생각이 포함되어 틀릴수도 있습니다)
regplot를 이용하여 PER(방 하나당 가격)과 MEDV(주택 가격)의 상관관계를 데이터 시각화를 해봤다.
상관관계가 `양의 관계`를 띄는 것을 볼 수 있다.(개인적인 생각으로 PER을 MEDV과 RM을 이용해서 계산했으니, 당연히 상관관계가 높은거 아닌가???)
regplot은 선형회귀분석처럼 데이터들의 선형성을 확인하는 그래프이다.
scatter plot과 line plot을 동시에 보여준다.
PER(방 하나당 가격)의 통계정보
# PER(방 하나당 가격)의 통계정보
df['PER'].describe()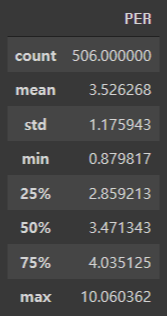
PER를 고가, 중가, 저가로 구분
# PER에 대해 고가,중가,저가로 구분
def per_func(x):
if x < 1.18: # std(표준편차)
return '저가'
elif x < 3.6: # 평균
return '중가'
else:
return '고가'
df['PER_1'] =df['PER'].map(per_func)
df.head()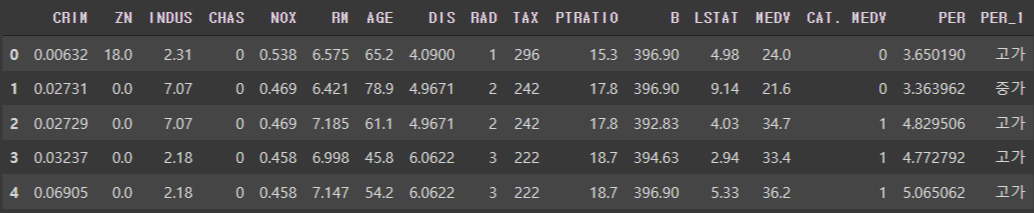
CASE 1의 결론
PER(방 하나당 가격)이 높을수록, MEDV(주택가격)이 높아진다.
CASE 2. 좋은 환경(일산화질소 농도, 찰스강)이 주택 가격에 영향을 줄 것인가?
가설
좋은 환경일수록, 주택 가격이 비쌀 것이다.
좋은 환경은 일산화질소 농도가 낮고, 찰스강이 보이는 환경을 의미한다.
그룹화해서 주택가격 평균보기
# CHAS와 NOX_GUBUN을 기준으로 MEDV의 평균을 그룹화
df.groupby(['CHAS','NOX_GUBUN']).mean()[['MEDV']]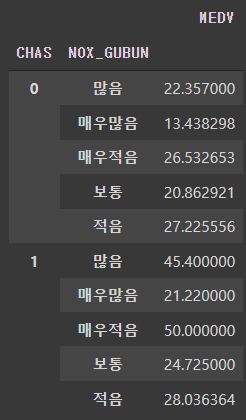
그룹화를 정렬
# 그룹화를 MEDV 기준으로 정렬
df.groupby(['CHAS','NOX_GUBUN']).mean()[['MEDV']].sort_values(by = ['MEDV'], ascending=False)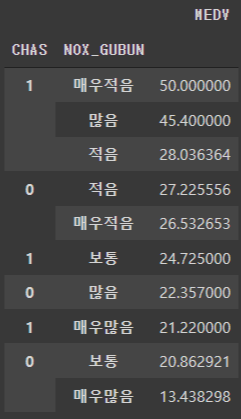
분석
가설과 동일하게
CHAS는 1, NOX_GUBUN이 매우적음 일때, 주택가격이 제일 높은 것을 알 수 있고,
CHAS는 0, NOX_GUBUN이 매우많음 일때, 주택가격이 제일 낮은 것을 알 수 있다.
하지만!!
두 번째로 높은 가격은 CHAS는 1, NOX_GUBUN이 많음 일때, 45.4이다.
가설에 의하면 이 조건에서는 높은 가격을 유지해서는 안된다.
그렇다면, 왜 높은 가격을 유지할까?
이에 대해서는 누군가 알려주면 좋겠다.ㅎㅎ😅😅
그 외의 주택가격은 20~28 사이로 큰 차이가 없으므로 큰 의미가 없다고 판단된다.
CASE 2의 결론
좋은 환경(일산화질소 농도가 낮고, 찰스강 경계에 위치)일 때, 주택가격이 높은것을 알 수 있다.
다만,
2번째로 주택가격이 높은 경우에 대해서는 추가적인 데이터 분석이 필요해 보인다.
728x90